廿柒- 客制化爬虫以及爬虫调参
1. 前文提要
前期用 Python 做了某些爬虫,但是发现有几个问题:
- 爬的
内容有很多未完全读取网页内容的信息 - 前期只爬取
tag为<p>的信息,但其实很多内容在<div>中,但直接爬<div>会有很多垃圾信息 - 广告页面信息清理
前期文章:
廿陆- Python 爬虫 异步改为同步加多进程 以及 某著名社交网站爬虫设想
2.关于客制化爬虫
2.1 信息内容捉取
例如天涯论坛,你会看到很多内容均存在在 div 中而不是在 p 中,但如果把所有 div 爬下来就会存在很多垃圾信息,于是需要针对它进行定制化。
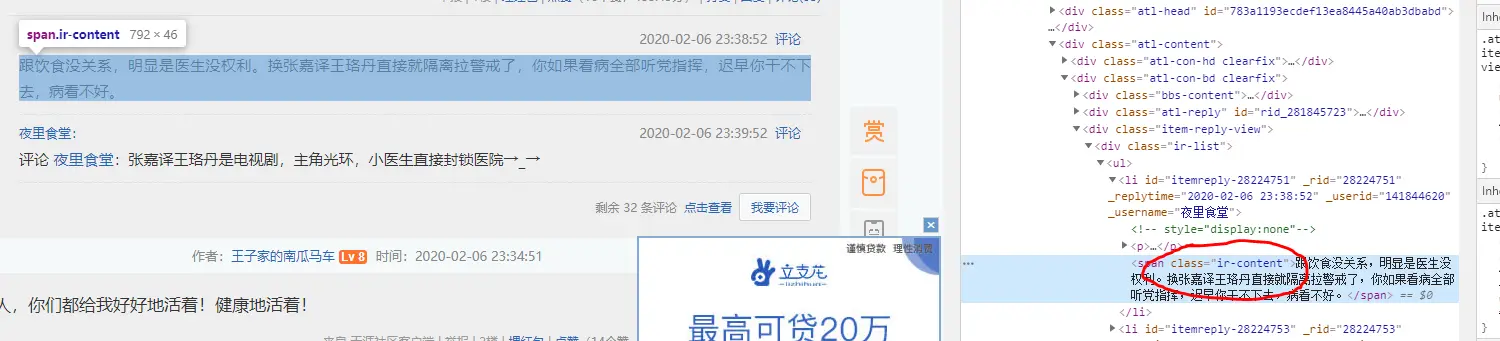

所以这个时候,我们就需要爬下 class 为 ir-content 以及 BBS-content 的内容。
2.2 爬取链接
链接方面,前期爬取的很多链接都是只要有 HTTP 开头的才捉取,导致很多内容确实,如以下这种是不保存的:
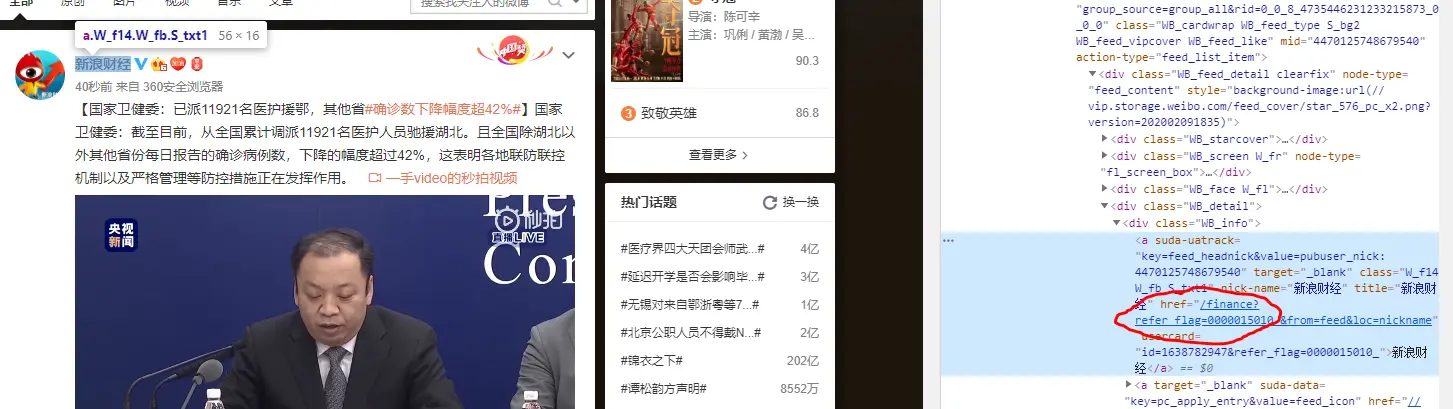
针对需客制化的网站捉取时,只捉取站内的链接,并不捉取外联,例如知乎的网站就只捉取知乎站内的链接,不捉取站外的链接。
2.3 客制化配置
关于针对需客制化网站的配置,如果无太多其他需求的话,如:
- 捉取网站用户的关注、粉丝等关系
- 捉取针对客户评论、被评论与正文内容分开
- 捉取用户活跃度
- 等等
如唔需上述信息只需简单的配置少量配置即可,以下是配置内容:
{ //微博
'eURL':'https://weibo.com/', // 配置门户页面
'tag':'.WB_text', //配置捉取内容配置
'rURL':'weibo.com' //配置URL补完信息
},
{ //微博
'eURL':'https://bbs.tianya.cn/', // 配置门户页面,第一层搜索的页面
'tag':'.bbs-content,.ir-content', //配置捉取内容配置,会捉取网页tag内参数为 class='bbs-content' 或 class='ir-content' 的
'rURL':'bbs.tianya.cn' //配置URL补完信息,补完后如 '/1024' 链接会变成 'bbs.tianya.cn/1024'
},
2.4 关键代码
完整的代码在全球大型同性交友平台 SpyTheLinkForCustomization 上。
其中针对链接捉取为如下:
aFromWeb = soup.select('a')
for eleA in aFromWeb:
strSpyURL = eleA.get('href')
if not strSpyURL is None and len(strSpyURL):
if len(strSpyURL)>4:
if strSpyURL[:4] != 'http':
if strSpyURL[1] == '/':
objAddPage.AddToDB('https:'+strSpyURL)
elif strSpyURL[0] == '/':
objAddPage.AddToDB(
'https://'+strInRURL+strSpyURL)
elif strSpyURL[:4] == 'http':
objAddPage.AddToDB(strSpyURL)
针对内容的捉取如下:
arrWebP = soup.select(strInTag)
objAddPage.AddPContent(arrWebP)
3. Python 爬虫调参
因为我用了很多免费的代理,所以发现爬出来的很多信息均为未读取完成的信息。
所以我可能必须得调整每次读取网页的时间。
但是这样却会影响爬虫的速度现在基本15分钟只能爬4个网页。
我发现现在网络上的免费代理要读取完一个网页基本是需要花30秒,其实优化只能缩短代理等待 timeout 的时间,发现能读取的网页时延长读取时间。
另外有一个可以解决的办法就是,偶尔不用代理进行链接。这样可以缩短等待时间。
4. 按关键字清晰爬取样本
捉取的很多网页都是广告这个问题,十分头痛。
于是我决定解决一下。
本来我打算是用智能一点的方法的,但我还是决定使用一些比较笨的方法,设定关键字。
但我很懒惰。所以还是来日再做吧。