叁拾- Pandas 整理某些原始数据格式 - 类交叉表式生成报表的数据帧处理 以及中括号的妙处
1. 写数据处理类 Python 代码的工具
当然就是鼎鼎大名的朱庇特了!
可以先把代码在这里运行,直接查看结果,再把完成的代码 Copy 到工程上,就省去往来调试的麻烦了。
Windows 下直接下载安装就可以了。
2. Pandas 读取 Excel 是怎样的呢?
我们现在有两个 Shit:
那么从 Pandas 导入这两个 Sheet 会怎样的呢?
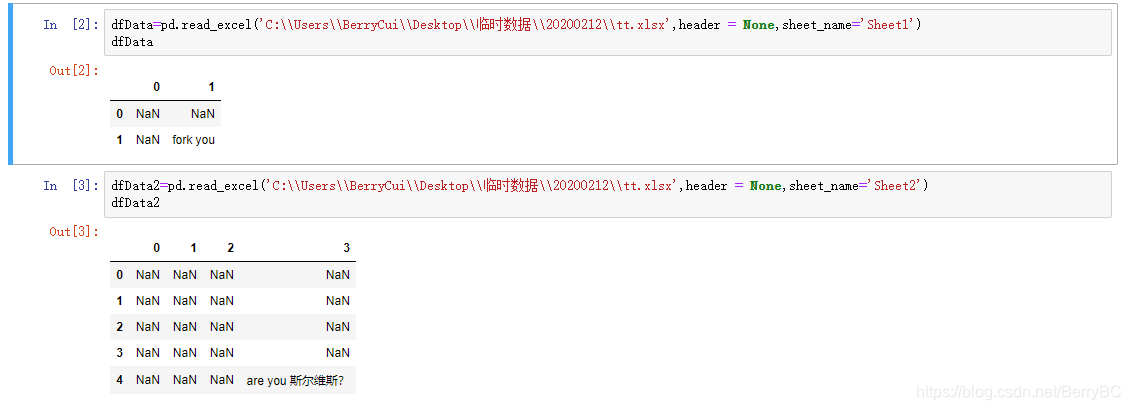
在什么都不设置的情况下,Pandas 是默认从 Excel 表的最左上侧读取的,而不是读取第一个有数据的行和列。
3. 数据源
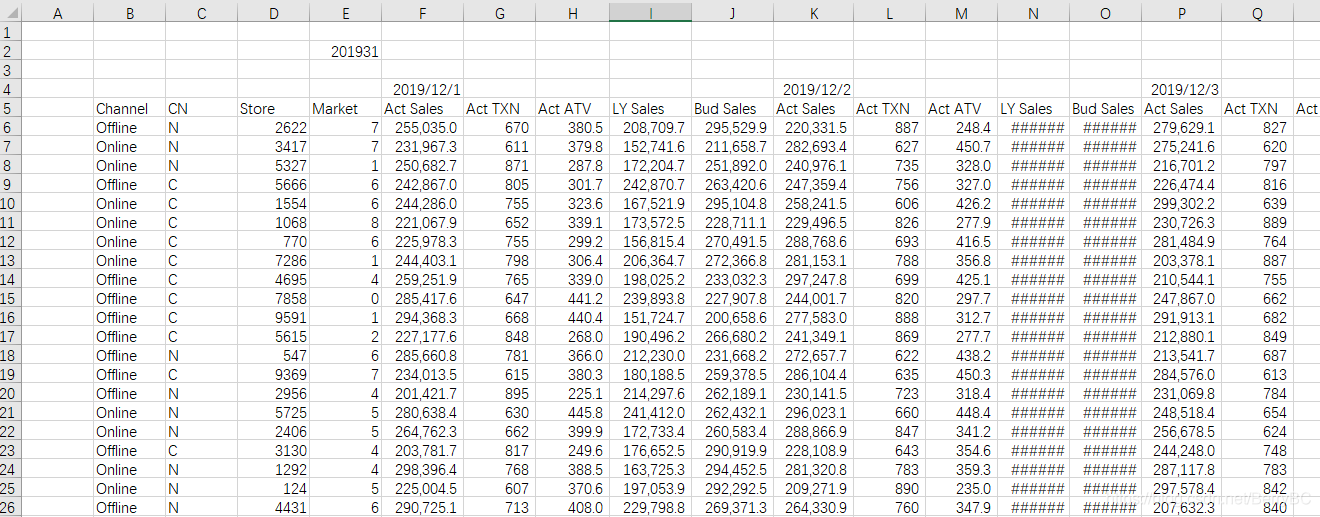
- 在
E2 单元格是当前数据的某个时间标识(当前数据源是'周'); - 可以看得出第4行跟第5行都是
标题数据;
其中第4行是日期标识,
第5行是字段内容标识
- 数据B列-E列为单都数据
归属标识 - 数据列F列-J列为对应F4单元格日期的
数据内容
4. 转换目标格式
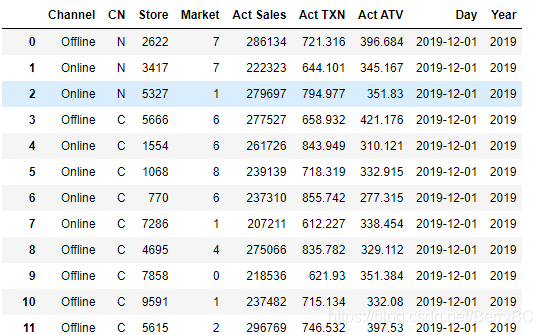
5. 工作前需注意事项
程序语言与日常的数数不一样,是从 0 开始的,而不是从 1 开始的(但我其实 VB 某些数据类型返回是从 1 开始数的,我也不知道是什么心态了)。
所以注意,Pandas 中 数据帧的行和列的位置跟 数据源 的行号是不一样的!
6. 简单处理开始
因为本文只是简单处理数据格式调整,未涉及数据内容处理,相关后事请看后文。
6.1 准备
# 引入包
import pandas as pd
import time
import numpy as np
# 此处引入数据
# 是的,我是 Windows 用户,怎么了!?不给么!?哼!
dfWeeklySales=pd.read_excel('C:\\Users\\BerryCui\\Desktop\\TempData\\20200110\\qq.xlsx',header = None)
# 此处初始化数据
arrSales=[5,10,15]
arrTXN=[6,11,16]
arrATV=[7,12,17]
arrTime=dfWeeklySales.iloc[3][[5,10,15]].tolist()
arrTime
intYear=2019
intDayNum=3
# 此处定义一个空白的数据帧存放数据
dfShow=pd.DataFrame(columns=['Channel','CN','Store','Market','Act Sales','Act TXN','Act ATV','Day','Year'])
上述代码描述了如何初始化位置参数,当然实际上面对的表格可能并不是固定格式(即相应数据内容并不固定行)的,但本文只针对固定格式进行说明。
(其实判断对应内容位置的代码在别的文章,别随便告诉人)
另外还存设定了一个空白的数据帧以存放整理后的数据。
6.2 转换
开始了哦,别眨眼了哦!
for intI in range(intDayNum):
dfTmp=pd.DataFrame(dfWeeklySales[~dfWeeklySales.iloc[:,[3]].isnull().values &
(dfWeeklySales.iloc[:,[3]]!='Store').values].iloc[:,[1,2,3,4,arrSales[intI],arrTXN[intI],arrATV[intI]]])
dfTmp.columns=['Channel','CN','Store','Market','Act Sales','Act TXN','Act ATV']
dfTmp.insert(len(dfTmp.columns),'Day',arrTime[intI])
dfTmp.insert(len(dfTmp.columns),'Year',intYear)
dfShow=dfShow.append(dfTmp,ignore_index=True)
好了,完事了。
6.3 关键解释
6.3.1 关于两个中括号(方括号)
其实如果有学过 R语言 的人,估计也会经历类似的伤心事。
上述代码中:
dfWeeklySales.iloc[3][[5,10,15]]
为什么会有 一个中括号里再包含一个中括号呢?
原因参看文章 Pandas中loc,iloc与直接切片的区别 :
直接索引索引的是列,方口号里面的内容一般是列索引名。也可以接受一个列名组成的list来接受多个列名。
6.3.2 获取数据帧中非空数据
对于 Pandas 空数据处理、数据过滤、查找空值等方法在基础教程里面有很多,一下为查找第4列非空的数据:
dfWeeklySales[~dfWeeklySales.iloc[:,[3]].isnull().values]
其中 ~dfWeeklySales.iloc[:,[3]].isnull().values 为第4列非空的行,~ 的意思是否。
那为什么要加 .values 呢?
.values 的意思是从 数据帧转换为:numpy.ndarray 类型。
如果你不是放 numpy.ndarray 到中括号中,而是放 数据帧(pandas.core.frame.DataFrame),例如:
dfTT=pd.DataFrame([[True,False,True,True,True,True],
[True,False,True,True,True,True],
[True,False,True,True,True,True],
[True,False,True,True,True,True]])
dfWeeklySales[dfTT]
你将会得到:
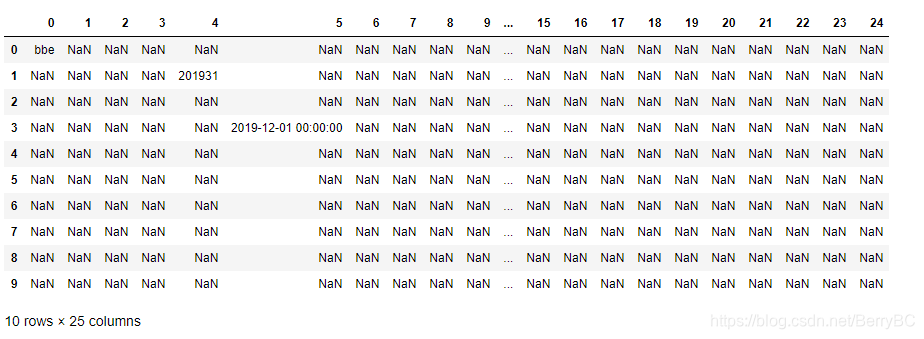
其实,就是在原数据帧(dfWeeklySales)中,对应新数据帧(dfTT)内容为 True 的数据。
是不是很简单呢~
6.3.3 原理
for 循环一共循环了3次(定义数据源只有3天的数据,提取数据表头内容的方法将在后续文章撰写)。
然后分别把3天的 'Act Sales','Act TXN','Act ATV' 以及数据归属放到一个临时的数据帧。
再把每天的数据帧合并到一起就行了。
7. 关于后事
三世书之所以重要,即需了解任何人事物的前世、今生、来世。
事物的前世包括它的形成、来源、意义等;
事物的今生包括它现在的形式、组成、链接外在的链接接口等;
事物的来世包括它可能引起的后果、即将前往何处、会与谁进行交互等。
了解前世需要相关经验,了解今生需要知识,了解来世需要用意识,我们必须靠努力的不断学习,不断充实自己,才能得到我们想要的结果,不然我们只能不断在原地迷惘,进而堕入修罗之道。
之后就把前期做好的表头查找形式、以及部分技巧继续存续下来,以便能让他们更好的保存下来,对自己的未来以及未来的你能有更大的裨益。
别误会,我不是雷锋,我只是崔秉龙,最后这一段纯粹是凑字数。
刚好4000字了,我好累啊。