陆拾贰- 机器学习包 Tensorflow - Python 版 输入空特征的反应
一、为何有此想法
最近想做出一个不需要不断重新训练的模型,就是只需要把某些对应特征输入,然后得到相应的结果,例如:
| 样本 | 特征1 | 特征2 | 特征3 | 特征4 | 特征5 | 特征6 | 问题1 | 问题2 | 特征7 |
|---|---|---|---|---|---|---|---|---|---|
| 样本1 | 1 | 0 | (空值) | (空值) | (空值) | (空值) | 1 | (空值) | (空值) |
| 样本2 | 0.8 | 0.3 | 0.8 | 0.1 | 0.1 | 0.1 | 1 | 1 | (空值) |
| 样本3 | 0.9 | (空值) | (空值) | (空值) | 0.3 | 0.1 | (空值) | 1 | 0.9 |
直接输入到一个黑匣子内
该黑匣子至少有以下几项功能:
- 可以输入不定量特征,黑匣子自适应
- 黑匣子自身能不断根据特征进行训练
- 黑匣子能根据不同的问题输出答案
- 黑匣子设定好之后不需人工干预
- 黑匣子能自己调用不同的人工智能包
所以第一阶段需考证一下
二、先随机一个测试集
先设定一个训练集
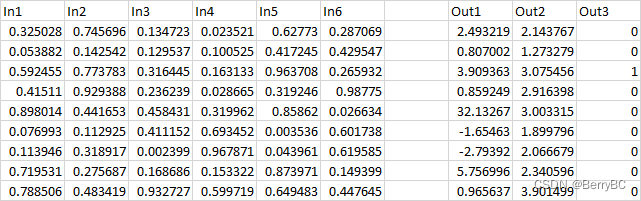
并把数据完整放到包内进行学习(就直接抄官网代码),代码如下:
import tensorflow as tf
import numpy as np
import InputData
from tensorflow import keras
from tensorflow.keras import layers
from tensorflow.keras.layers.experimental import preprocessing
x_train,y_train,x_test,y_test = InputData.TestData()
# x_train,y_train,x_test,y_test = InputData.TestBlankData()
print(len(y_test))
x_train=np.array(x_train).astype(np.float64)
y_train=np.array(y_train).astype(np.float64)
x_test=np.array(x_test).astype(np.float64)
y_test=np.array(y_test).astype(np.float64)
# x_train[np.isinf(x_train)]=0
# x_train[np.isnan(x_train)]=0
# x_test[np.isinf(x_test)]=0
# x_test[np.isnan(x_test)]=0
horsepower_normalizer = preprocessing.Normalization(axis=1)
horsepower_normalizer.adapt(x_train)
model = tf.keras.models.Sequential([
horsepower_normalizer,
tf.keras.layers.Dense(6, activation='relu'),
tf.keras.layers.Dense(10, activation='relu'),
tf.keras.layers.Dense(6, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(2, activation='softmax')
])
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
model.fit(x_train, y_train[:,2], epochs=500)
model.evaluate(np.array(x_test), np.array(y_test)[:,2])
test_predictions = model.predict(x_test)
test_result=[0,0]
for intI in range(len(test_predictions)):
print(str(intI)+' : Pre - '+str(test_predictions[intI])+' , Act - '+str(y_test[intI][2]))
if((test_predictions[intI][0]>0.5 and y_test[intI][2] ==0) or (test_predictions[intI][1]>0.5 and y_test[intI][2] ==1) ):
test_result [0]+=1
else:
test_result [1]+=1
print('[正确,错误]')
print(test_result)
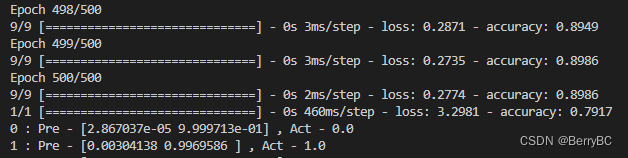
得出结果为:
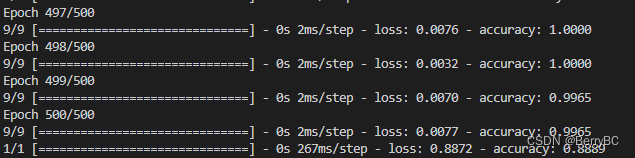
对于测试集有 89% 正确
三、测试集中插入空值
如下图所示,把测试集的数据随机插入空置

同样运行代码,得出结果为:
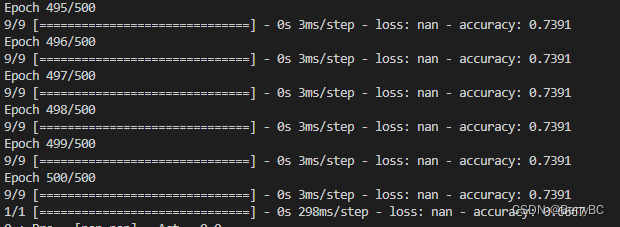
因为结果含有空置,所以模型直接收皮了
四、把空置替换为 0
加入代码:
x_train[np.isinf(x_train)]=0
x_train[np.isnan(x_train)]=0
x_test[np.isinf(x_test)]=0
x_test[np.isnan(x_test)]=0
结果比原本差了不少
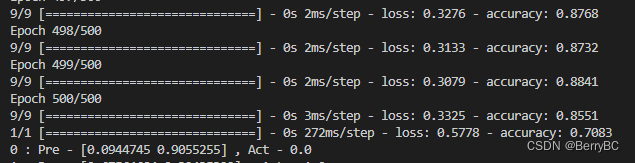
五、把空置替换为 随机数
我不知道为什么,不过我觉得0不好看,我就替换成随机数了,结果提升了
六、没啥结论
我就是尝试一下而已,个人认为,单独一个模型的调优以及设置其实并没有太大的意义
只要知道机器学习的原理以及知道如何应用,调优可以交给专门其他人,甚至现在有很多人沉迷于此(但这些人只沉迷于准确率,却没想过业务变化的话,之前调整好的模型应该如何去适应)
但如何使用模型,把模型放到一个更有价值的地方去使用,把不同的模型整合,把模型跟业务实际的结合,反而是现在很多人没有想过的方向
努力,腰痛啊