柒拾陆- AI内容农场生产文章自动发布至公众号 (二)
一、Run 了半天的结果
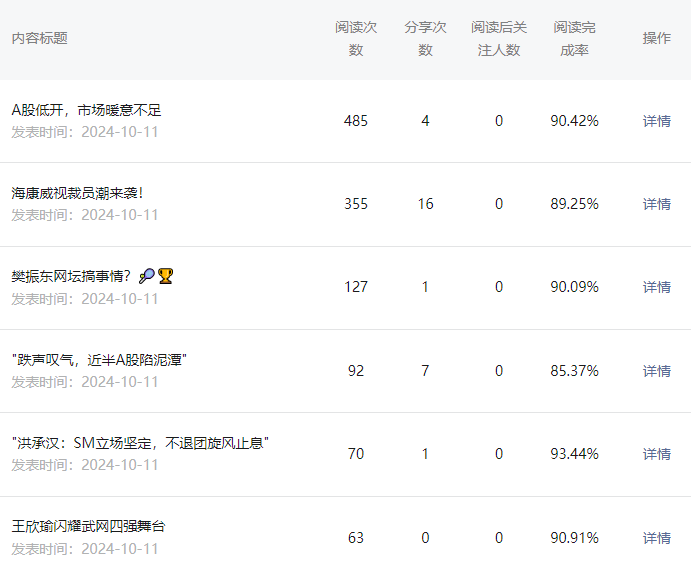
白天放着代码就在这里 run ,大概吐了 260 篇文章,因为没有专门优化内容 ( AI 吐什么就发什么 ) 以及没有进行发表 ,所以浏览量跟转发量均不多。

其中最多的都是经济类的比较火 ( 也有可能是明星名人类太多内容农场搞了 )
二、代码结构
整体代码都是一页过,没有进行工程化的模块拆分 ( 因为就是看能不能跑通 )
代码分了3大块
- 配置 ( 数据库配置、API Key 的配置 )
- 用到的功能模块写成函数 ( 例如请求 Token 、搜图片、 AI 生成文章 等 )
- 主流程代码
其中的 主流程代码 分了 8 个部分
- 链接本地数据库
- 获取发布文章的 Access Token
- 获取微博热搜关键词列表
- 搜关键词相关图片
- 下载搜到的图片
- AI 自动生成文章 (定好关键词)
- 上传文章
- 发布文章
三、开始拆解
配置
首先做一个 Top 变量存各种配置
dictGblCfg = {'offiAccAppid': '1024',
'offiAppSecret': '1024',
'offiAccToken': '',
'hotSearchKeywordList': [],
'bigModelKey': '10241024',
'mysqlPW':'1024',
'mysqlUser':'LoveSummer',
'mysqlPort':1024,
'mysqlDB':'db_genarticle',
'mysqlHosts':'127.0.0.1',
'mysqlConn':None
}
方便调用时不会跟 其他变量 撞名 ( 其实脚本语言本来就对变量名不严格要求,特别在 Python 连声明也不用就更容易出错了 )
1. 链接 MySQL
前期已经在 SQL 上建好表
-- 导出 db_genarticle 的数据库结构
CREATE DATABASE IF NOT EXISTS `db_genarticle` /*!40100 DEFAULT CHARACTER SET utf8 */;
USE `db_genarticle`;
-- 导出 表 db_genarticle.tb_hotsearch 结构
CREATE TABLE IF NOT EXISTS `tb_hotsearch` (
`word` varchar(300) DEFAULT NULL,
`create_time` datetime DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
然后在主流程上加上链接数据库,并把链接放到配置表里面
因为前期把链接数据库跟配置放在一起,这里就不改 Wording 了
# -----------------------------------------------------------------------
# 一、配置整体配置
try:
dictGblCfg['mysqlConn'] = mysql.connector.connect(
host=dictGblCfg['mysqlHosts'], user=dictGblCfg['mysqlUser'], password=dictGblCfg['mysqlPW'], port=dictGblCfg['mysqlPort'], database=dictGblCfg['mysqlDB'])
connLog = dictGblCfg['mysqlConn']
strLogSQL = "INSERT INTO db_genarticle.tb_hotsearch (word, create_time) VALUES ('我开机了', now())"
connLog.cursor().execute(strLogSQL)
# 提交事务
connLog.commit()
except Exception as e:
print(f'一、配置 方面错误,错误为 : {e}')
2. 获取发公众号的 Access Token
公众号 Access Token 的作用除了上传图片之外,还有上传文章、发表之用
反正就是所有跟公众号交互的都需要以 Access Token 做 Token ( 好像是一个废话 )
# -----------------------------------------------------------------------
# 二、获取微信 Access_Token
try:
dictGblCfg['offiAccToken'] = funGetOffiAccAccToken(
dictGblCfg['offiAccAppid'], dictGblCfg['offiAppSecret'])
# print(dictGblCfg['offiAccToken'])
except Exception as e:
print(f'二、获取微信 Access Token 方面错误,错误为 : {e}')
3. 获取微博热搜
获取实时的 热搜关键词 ,就没有太复杂的防爬虫 ( 估计他也认为这随便爬吧,也没意义 )
# -----------------------------------------------------------------------
# 三、Fetch the hot search data
try:
dictHotSearch = funFetchWeiboHotSearch()
listHotSearch =dictHotSearch['data']['realtime']
# 这里作为测试时是否获取正确了
# print(strKeyword)
listKeyword = funInsertWordsIfNotExists(dictGblCfg['mysqlConn'],listHotSearch)
except Exception as e:
print(f'三、获取微博热搜 方面错误,错误为 : {e}')
4. 搜相关图片
根据关键词找到需要发布的图片
# -----------------------------------------------------------------------
# 四、搜相关图片
try:
listKeywordPic = funGetPicture(strGenKeyword)
except Exception as e:
print(f'四、搜个图片 方面错误,错误为 : {e}')
5. 下载相关的图片并上传
下载前期搜到的图片
然后上传到公众号,并获取 Media ID ( 作为封面的时候需要这个 ID )
# -----------------------------------------------------------------------
# 五、下载图片
listImgList = []
listImgMediaID = []
try:
for strAKeywordPic in listKeywordPic[:3]:
# 测试时看关键词有没有错
# print(strAKeywordPic)
strImgFile = funDownloadImage(strAKeywordPic)
# 看下载的图片路径
# print(strImgFile)
listFBOffiImg=funUploadImgToOffiAcc(dictGblCfg['offiAccToken'], strImgFile)
listImgList.append(listFBOffiImg['url'])
listImgMediaID.append(listFBOffiImg['media_id'])
except Exception as e:
print(f'五、下载图片 方面错误,错误为 : {e}')
6. 写文章
开始请求大模型,并写文章,简单的看到,文章跟标题是分开生成的 ( 因为我不想再做内容匹配,好麻烦 )
也不想再优化 提示词 了,不知道是不是我请求的模型比较笨,无论怎么调整 提示词,还是整天会有乱起八糟的东西
例如我希望它直接吐出 HTML,它硬是要加上 ````html` 这些字眼,气死我了
其实如果可以 优化提示词 ,或者用 更好的模型,或者多个模型进行 交叉审核 就能生成看起来更好的文章
# -----------------------------------------------------------------------
# 六、写文章
strTitle='默认标题'
strArticle='默认内容'
try:
client = ZhipuAI(api_key=dictGblCfg['bigModelKey']) # 填写您自己的APIKey
response = client.chat.completions.create(
model="glm-4-flash",
temperature=1,
top_p=1,
messages=[
{"role": "system", "content": '''
你是一个文采风趣的作家,内容是结合时下热点输出文章,要求:
1.输出内容需要以 HTML 的格式(并只生成 <body> 之中的内容,但不需要包含 <body> 标签)。样式需要在标签中的 Style 给出。
2.每篇文章需要在800字左右。需要在最后加入一行 3px 的白色字,内容是“文章由AI生成”,必须要是白色 3px 的!!!
3.不需要以 Markdown 形式展示,直接输出能运行的 HTML 代码。
4.偶尔插入星巴克的软性广告。
'''},
{"role": "user", "content": "帮忙根据关键词 '"+strGenKeyword +
"' 生成文章,并在其中加入图片,图片 URL 如下:'"+"','".join(listImgList)+"'"},
],
)
strArticle = response.choices[0].message.content
# print(strArticle)
if strArticle[:7] == "```html":
strArticle = strArticle[7:]
strArticle = strArticle[:-3]
response = client.chat.completions.create(
model="glm-4-flash",
temperature=1,
top_p=1,
messages=[
{"role": "system", "content": "你是一个文采风趣的作家,内容是结合时下热点输出简单不超10字的文章标题,仅需输出标题,不需要输出其他东西,且标题需要抓人眼球"},
{"role": "user", "content": "帮忙根据内容 '"+strGenKeyword+"' 生成标题"},
],
)
strTitle = response.choices[0].message.content
# print(strTitle)
except Exception as e:
print(f'六、写文章 方面错误,错误为 : {e}')
if listImgMediaID[0]==None:
listImgMediaID[0] = '0'
dictOneArticle={
"title": strTitle,
"author": '吴教授',
"content": strArticle,
"thumb_media_id": listImgMediaID[0],
"need_open_comment": 1,
"only_fans_can_comment": 0,
}
listArticle.append(dictOneArticle)
7. 上传文章
简单的上传
# -----------------------------------------------------------------------
# 七、上传文章
try:
dictPublishStatus=funPublishDocument(dictGblCfg['offiAccToken'],listArticle)
# print(dictPublishStatus)
except Exception as e:
print(f'七、上传文章 方面错误,错误为 : {e}')
8. 发布文章
终于发布了
# -----------------------------------------------------------------------
# 八、发布文章
try:
dictSubmitStatus=funSubmitArticle(dictGblCfg['offiAccToken'],dictPublishStatus['media_id'])
except Exception as e:
print(f'八、发布文章 方面错误,错误为 : {e}')
9. 有手尾一点
还得关闭我打开的数据库
try:
dictGblCfg['mysqlConn'].close()
except Exception as e:
print(f'关闭数据库链接 方面错误,错误为 : {e}')
四、看着 AI 写的文章,内心一阵拔凉
说真的,如果是以前,没人告诉我这是 AI 写的东西,我会感叹世风日下
文笔还算通畅,但内容一塌糊涂,睁着眼睛说瞎话,认认真真的胡扯
一代一代的垃圾投入又产出
大模型这类算法本身就是一个自限性的算法,期待以后能发展出真能进化的 AI 算法