柒拾柒- AI内容农场生产文章自动发布至公众号 (三)
一、效果
其实,垃圾的内容,是针对求真的人
而空闲的人,其实还对垃圾有非常高的需求,这是我这几天最大的感悟
以下是这个小实验最初要验证的两个效果
1) 垃圾内容居然还有人看
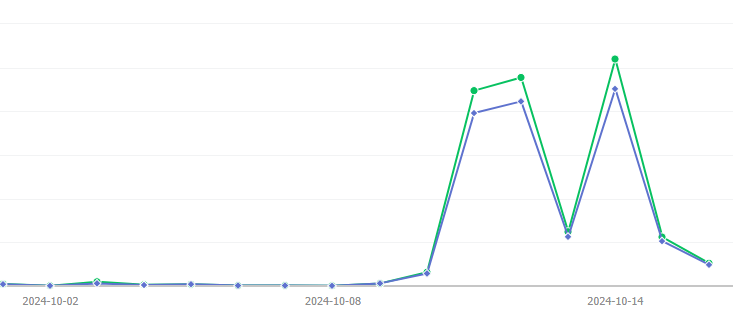
这个 AI 自动生成 垃圾文章 的实验让人感觉太绝望了,这些内容甚至在我没发的几天居然还有浏览以及转发
大家可以感受一下转发量最高的文章:
2) 不同模型生出来的文章质量还真有点差
同一段提示词,在不同的大模型上面生成的结果 ( 主要是内容通常度、排版 ) 还真的差很远,大家可以直观感受下:
- 差一点的模型
- 好一点的模型
二、针对不同 Function 的明细代码
因为代码也是由 大模型 生成的 ( 感觉整个 项目 都是来验证 AI 干活到底有多不靠谱 )
所以我决定拿出来每个 Function 出来吐槽以下
整体引用包
import requests
import json
from bs4 import BeautifulSoup
from urllib.parse import urlparse, parse_qs
from zhipuai import ZhipuAI
import mysql.connector
from datetime import datetime, timedelta
import asyncio
import time
import random
抓取微博热搜的函数
# -----------------------------------------------------------------------
# 函数 : 先抓取热搜
def funFetchWeiboHotSearch():
# Fetch the hot search data from Weibo's AJAX endpoint and return it as a dictionary.
url = "https://weibo.com/ajax/side/hotSearch"
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/129.0.0.0 Safari/537.36'
}
response = requests.get(url, headers=headers)
# Raises an HTTPError if the HTTP request returned an unsuccessful status code
response.raise_for_status()
return json.loads(response.text)
except Exception as e:
print(f"An error occurred: {e}")
return None
发布文章
其实我不是很理解为什么这里需要用 f”” 这个写法….
# -----------------------------------------------------------------------
# 函数 : 发布文章
def funSubmitArticle(strAccToken,strMediaID):
try:
# 设置API的URL
url = f"https://api.weixin.qq.com/cgi-bin/freepublish/submit?access_token={strAccToken}"
# 设置要发布的草稿的media_id
payload = {
"media_id": strMediaID
}
# print(url)
# print(strMediaID)
# 发送POST请求
response = requests.post(url, data=json.dumps(payload))
# 打印响应内容
# print(response.text)
dictFB = json.loads(response.text)
return dictFB
except requests.exceptions.RequestException as e:
print(f"An error occurred: {e}")
except Exception as e:
print(f"An unexpected error occurred: {e}")
去查 Google 的相关图片
我试过了,好像百度的话搜不了图 ( 用了 JS , 所以得用别的库,还要占用浏览器,不行 )
# -----------------------------------------------------------------------
# 函数 : 去查 google 相关图片
def funGetPicture(strInKeyword):
# 设置关键词和代理
# keyword = "易烊千玺谈恋爱"
proxy = {
'http': 'http://127.0.0.1:1024',
'https': 'http://127.0.0.1:1024'
}
# 返回的数组
listFB = []
# 搜索图片的URL
search_url = f"https://www.google.com/search?q={strInKeyword}&tbm=isch&udm=2"
# 设置请求头,模拟浏览器行为
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
}
try:
# 发送请求,使用代理
response = requests.get(search_url, headers=headers, proxies=proxy)
# 检查请求是否成功
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
# 查找图片链接
# print(soup)
images = soup.find_all("img", class_="DS1iW")
# images = soup.find_all("img")
# print(images)
for img in images:
try:
# 提取图片链接
img_url = img['src']
# img['src']
listFB.append(img_url)
# print(img_url)
except KeyError:
continue
else:
print("请求图片失败,状态码:", response.status_code)
except Exception as e:
print(f"An error occurred: {e}")
# return False
return listFB
下载相关图片
这段代码其实我改过了,因为大模型吐出来的代码,怎么说呢?
不能直接跑出来 ( 我估计人家写的是在 Linux 环境下,无法直接运行在 Windows )
# -----------------------------------------------------------------------
# 函数 : 下载相关图片
def funDownloadImage(image_url, save_dir="./img"):
"""
Download an image from a given URL and save it to a specified directory with the same name as in the URL.
Args:
- image_url (str): The URL of the image to download.
- save_dir (str): The directory where the image should be saved.
Returns:
- bool: True if the image was successfully downloaded and saved, False otherwise.
"""
proxy = {
'http': 'http://127.0.0.1:1024',
'https': 'http://127.0.0.1:1024'
}
# 设置请求头,模拟浏览器行为
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
}
# 准备返回的数据
strFBSaveImg = ''
try:
# Parse the URL to get the file name
# url_path = urlparse(image_url).path
# filename = url_path.split("/")[-1]
# 解析URL
parsed_url = urlparse(image_url)
# 提取查询字符串参数
query_params = parse_qs(parsed_url.query)
# 打印所有参数
# print("All query parameters:", query_params)
# 提取特定的参数
filename = query_params.get('q', [None])[0] # 返回值是一个列表,我们取第一个元素
filename = filename[4:]
# Ensure the save directory ends with a slash
if not save_dir.endswith("/"):
save_dir += "/"
# Full path where the image will be saved
strFBSaveImg = save_dir + filename
response = requests.get(image_url, headers=headers, proxies=proxy)
response.raise_for_status()
with open(strFBSaveImg, "wb") as file:
file.write(response.content)
except Exception as e:
print(f"An error occurred: {e}")
return strFBSaveImg
获取 Access Token
# -----------------------------------------------------------------------
# 函数 : 获取 Access Token
def funGetOffiAccAccToken(strAppid, strAppSecret):
# Fetch the hot search data from Weibo's AJAX endpoint and return it as a dictionary.
url = f"https://api.weixin.qq.com/cgi-bin/token?grant_type=client_credential&appid={strAppid}&secret={strAppSecret}"
try:
response = requests.get(url)
# Raises an HTTPError if the HTTP request returned an unsuccessful status code
response.raise_for_status()
dictFB = json.loads(response.text)
# print(response.text)
strAccToken = dictFB['access_token']
return strAccToken
except Exception as e:
print(f"An error occurred: {e}")
return None
上传图片
# -----------------------------------------------------------------------
# 函数 : 上传图片素材给那啥
def funUploadImgToOffiAcc(strAccToken, strFileName):
try:
# 设置API的URL
url = "https://api.weixin.qq.com/cgi-bin/material/add_material"
# 设置参数
params = {'access_token': strAccToken, 'type': 'image'}
# 设置表单数据
description = '{"title":"'+strFileName+'", "introduction":"'+strFileName+'"}'
files = {
'media': ('jj.jpg', open(strFileName, 'rb'), 'image/jpeg'),
'description': (None, description, 'application/json')
}
# 发送请求
response = requests.post(url, params=params, files=files)
# 打印响应内容
# print(response.text)
dictFB = json.loads(response.text)
return dictFB
except requests.exceptions.RequestException as e:
print(f"An error occurred: {e}")
except FileNotFoundError:
print(f"The file at path {strFileName} was not found.")
except Exception as e:
print(f"An unexpected error occurred: {e}")
上传文章
# -----------------------------------------------------------------------
# 函数 : 上传文章
def funPublishDocument(strAccToken, listArticles):
try:
# 设置API的URL
url = f"https://api.weixin.qq.com/cgi-bin/draft/add?access_token={strAccToken}"
# 构建请求的数据
data = {"articles": listArticles}
# 发送POST请求
response = requests.post(url, data=json.dumps(
data, ensure_ascii=False).encode('utf-8'))
# 打印响应内容
# print(response.text)
return json.loads(response.text)
except requests.exceptions.RequestException as e:
print(f"An error occurred: {e}")
except Exception as e:
print(f"An unexpected error occurred: {e}")
插入热搜到数据库中
每次需要把找到的热搜放到数据库中,如果前期已经做过的关键词这次是不再做的
# -----------------------------------------------------------------------
# 函数 : 插入热搜到数据库中
def funInsertWordsIfNotExists(connMySQL,listWords):
# 数据库连接信息
listFBWords=[]
# 录入多少个热点
intMax=5
intNow=0
try:
with connMySQL.cursor() as cursor:
# 获取当前时间
current_time = datetime.now()
# 计算10天前的时间
ten_days_ago = current_time - timedelta(days=10)
for word_dict in listWords:
# 检查word是否在数据库中,且create_time在10天内
sql_check = """
SELECT * FROM db_genarticle.tb_hotsearch
WHERE word = %s AND create_time > %s
"""
cursor.execute(sql_check, (word_dict['word'], ten_days_ago))
result = cursor.fetchone()
# 如果不存在,则插入
if result is None:
sql_insert = """
INSERT INTO db_genarticle.tb_hotsearch (word, create_time)
VALUES (%s, %s)
"""
cursor.execute(sql_insert, (word_dict['word'], current_time))
# 提交事务
connMySQL.commit()
listFBWords.append(word_dict['word'])
intNow=intNow+1
if intNow>= intMax:
connMySQL.close()
return listFBWords
except Exception as e:
print(f"An error occurred: {e}")
finally:
# 关闭数据库连接
connMySQL.close()
return listFBWords
三、结果
这个东西其实挺好玩的,但是真的是毫无意义
最近看了很多小红书养号的再卖钱,说白了….方法跟路径都是大把,但有没有意义,这些也不太长久的
好了,拜拜了
前文 :