咖啡店新开店扩展模式
1。前提
以下一切数据均来自于虚构的平行世界。
切勿当真。
2。为什么要新开店
- 1)假设红色星星是店的所在地,红色圆圈是该店顾客所在地(假设
顾客只选取附近的咖啡店光顾):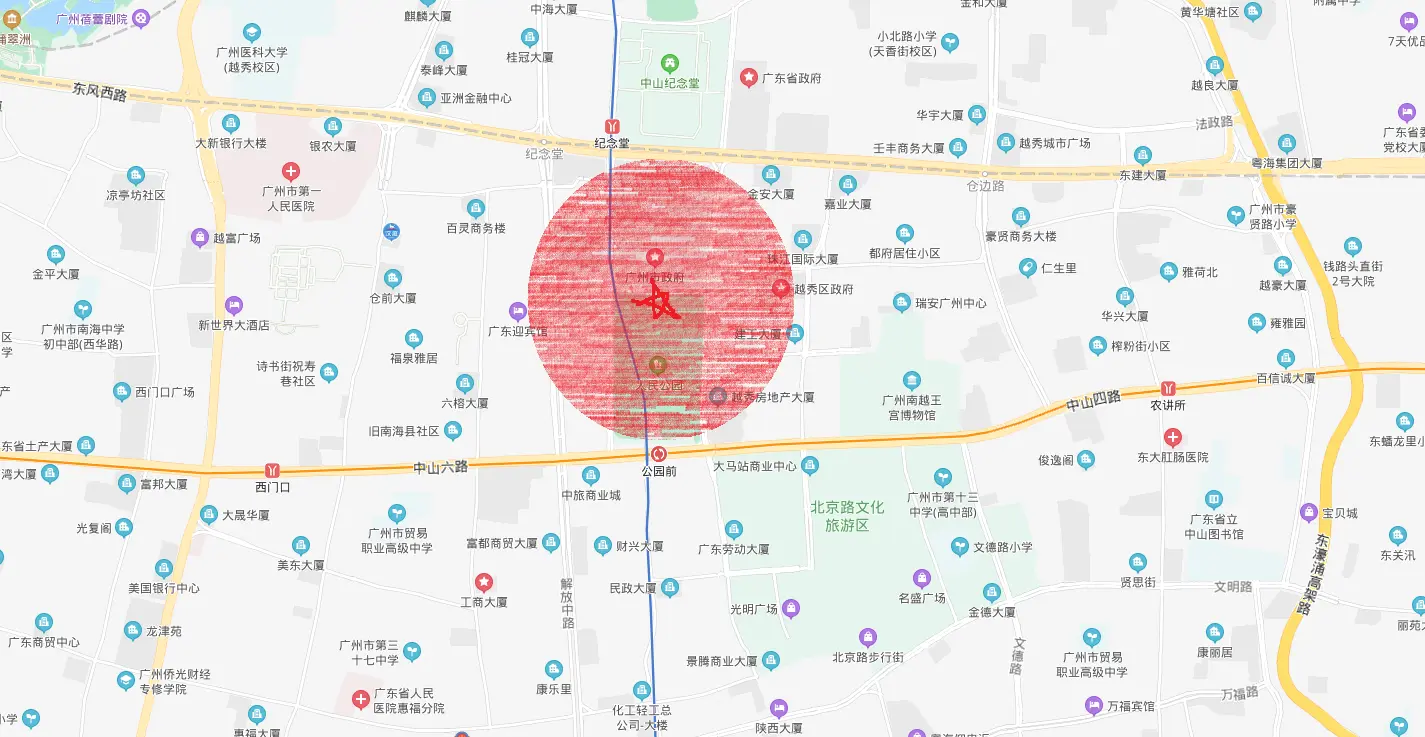
- 2)如果我们想吸引
更多顾客获取更多订单,而顾客又不肯走得太远,这时候我们必须贴近顾客,开多一家店: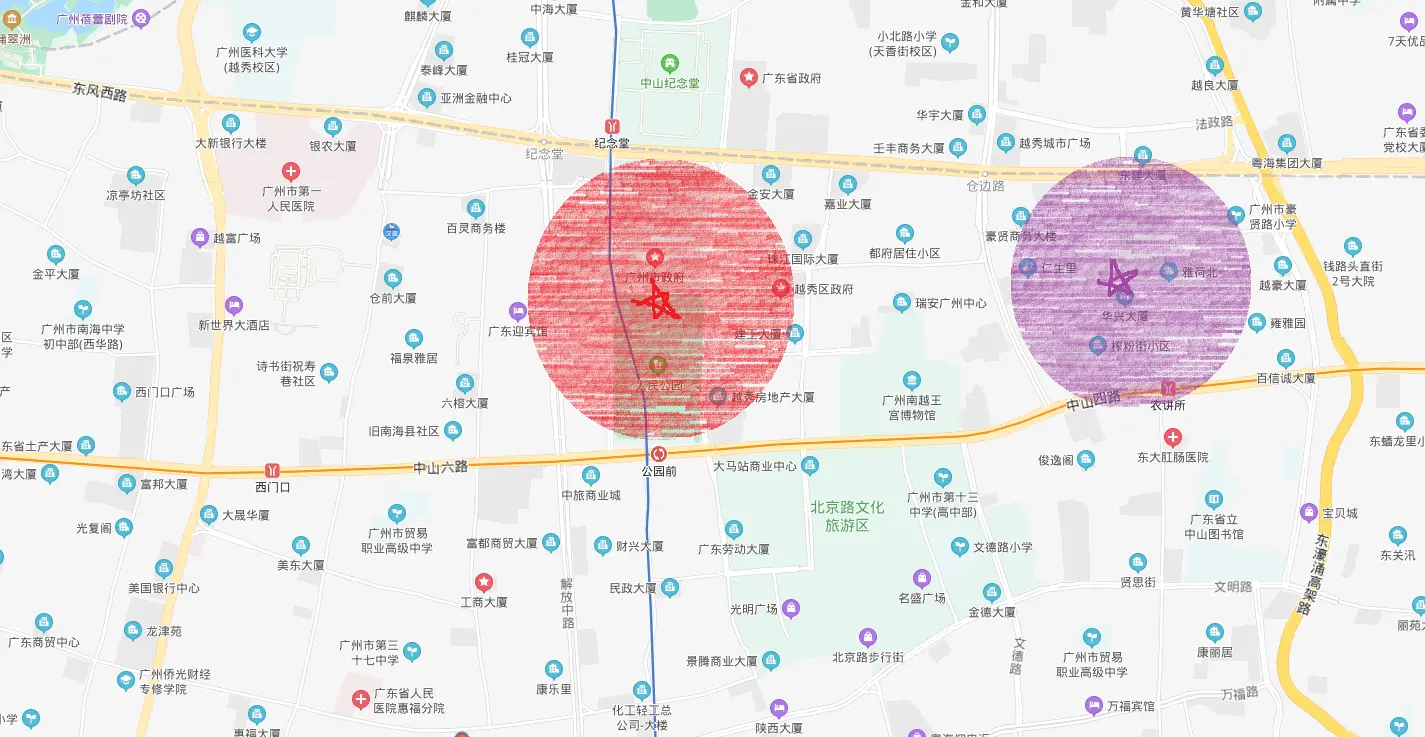
此时覆盖的范围更广了,能吸引更多的客户了,订单多了,钱赚多了(圆圈范围扩大)。
- 3)
贪得无厌的人类想开得更多店赚更多的钱了: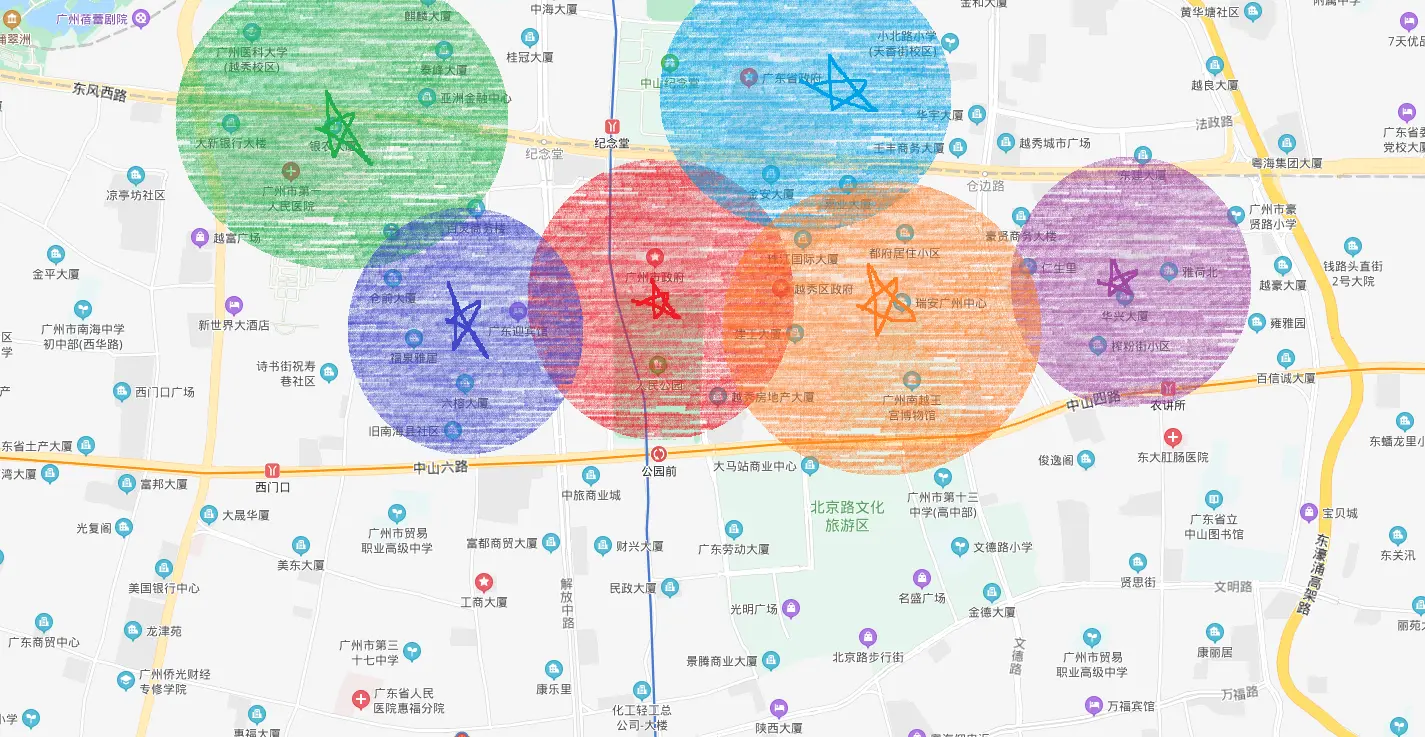
店开得多了,结果却发现覆盖区域有重复了,Shit。
3。开得越来越多新店会引起什么呢?
-
总的顾客数量会提升 因为开的
新店越多,覆盖的面积就越多,能勾引越来越多的本来不在覆盖范围的顾客。 -
每家店的顾客数量会下降 因为
重复区域会越来越多,使得同一位置的顾客有可能选择不同位置的咖啡馆。
4。开得越来越多新店会引起什么呢?
看下在某个时间点,广东某品牌咖啡店每天的顾客数量:
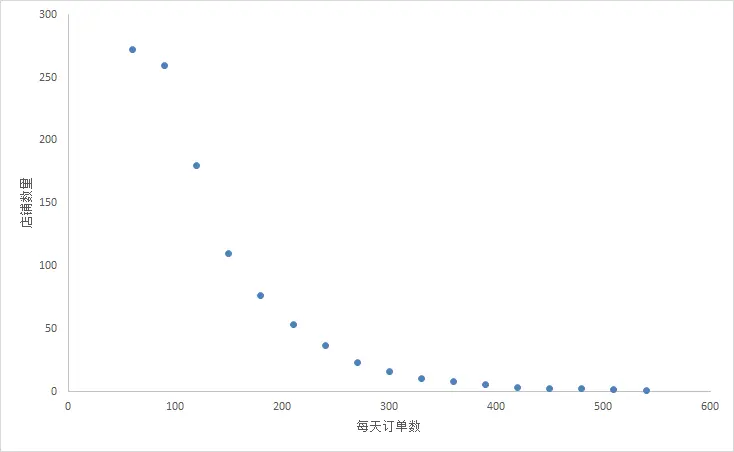
可以看出,顾客数量多的店铺会较少,且有较多店铺每天顾客数量较少(100个以内)。
这样看起来不舒服,我决定把坐标轴换一下,先对每天顾客数量取一个对数变换,变换后得出:
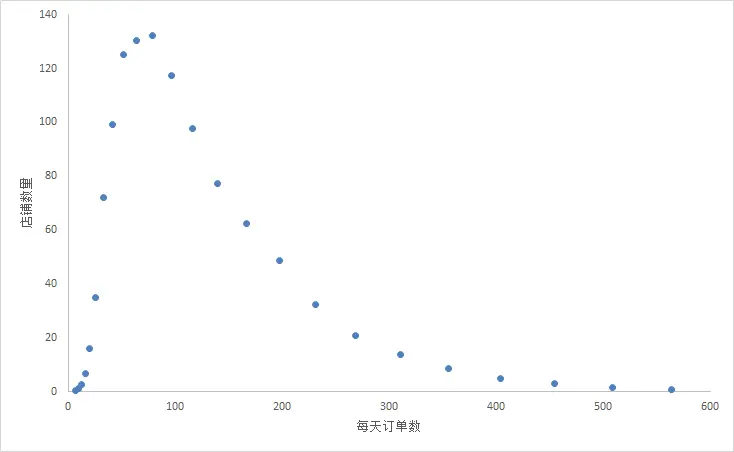
可以看出 X 坐标轴越靠近 0 的点越密集。
但是其实也不好看,于是我们决定继续对 X 跟 Y 轴进行归一化再对数处理。
得出:
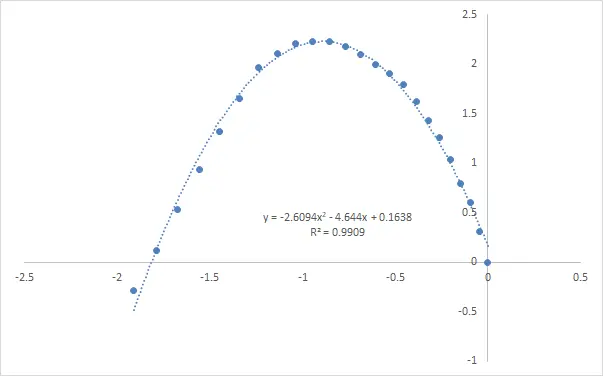
5。为什么我们需要进行对数处理?
因为非对数处理时,虽然也可以作为一个高斯分布来做回归得出分布,但其实大多数咖啡店仍然是集中在日顾客数量 0-100 ,我们的模型可能不能很好的对日顾客数量低的店铺进行分析。
6。研究不同店铺数量时的分布
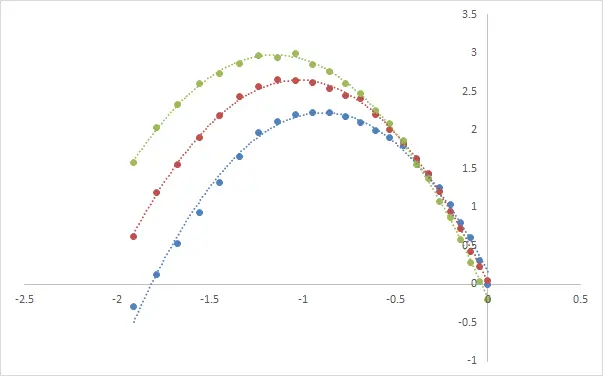
蓝色为4年前数据,红色为2年前数据,绿色为当前年份数据。
可以看出,不同年份的曲线均很好的符合一元二次方程分布,若我们对该方程3个较为特征的点(与X轴交点、顶点)进行回归:
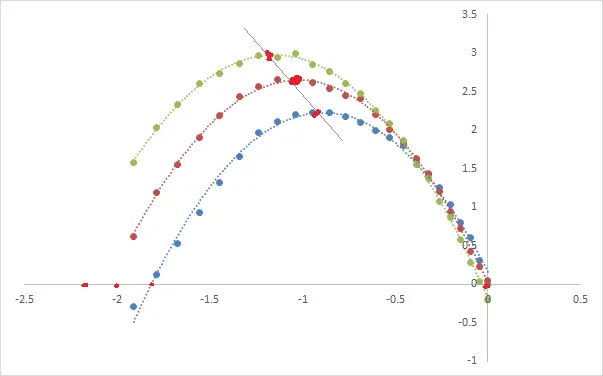
根据该省份咖啡店的数量以及日顾客数量的分布曲线特征点进行回归,可以得出,我开出多少家咖啡店,各店的日客户数量分布关系。
7。什么都看不出
我开出了多少家店,实际上每天会吸走其他店铺多少顾客,其实这个数是看不出来的。我只是睡不着在瞎说。当然如果有人能给个打赏会很好,我最近缺钱,烦请点击下方,然后输入金额,然后支付。